Web scraping in node.js 101
12 Mar 2018Web scraping is a great way to create dynamic websites or to just be able to get data from sites without having access to their databases. In short, it is an easy method to get info from a site by going through the front end (what the user sees) HTML code.
To get started with web scraping you must know how a website is structured. If you right click on a page, and click inspect (on chrome), you can see the developer tools.
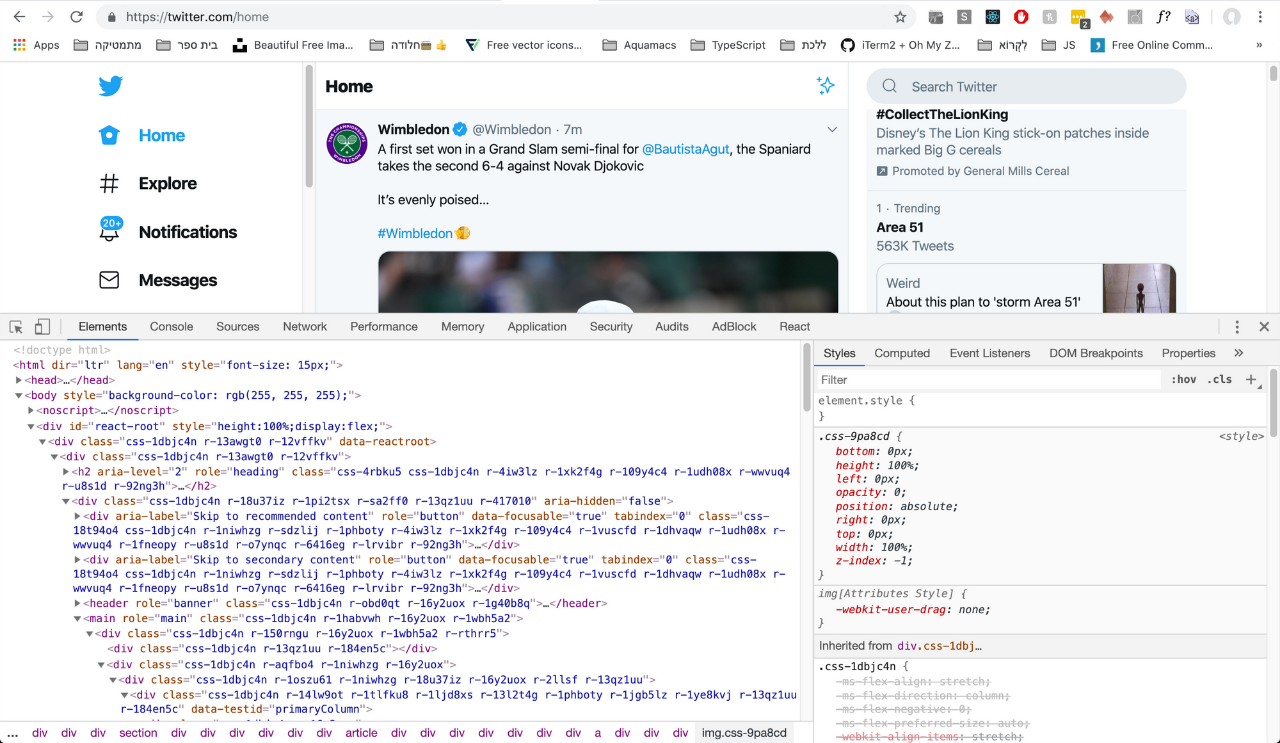
This shows you the structure of the HTML/CSS/JavaScript code as well as network performace, errors, security, and much much more.
Now, let’s say I want to grab the first image that you see on twitter programatically in the JavaScript console.
Well, I could right click on the image, click inspect, right click on the element in the dev tools, and copy the css selector.

Then I could do a document.querySelector(<<SELECTOR>>).src and that would give me the URL of the image I want, and I could use that on a web page, for example:

This IS web scraping! I was able to gather data (an image) from a website without having access to the database. But this is super tedious and long, so to actually webscrape more efficiently, I use Node.js + Puppeteer.
If you don’t already know, Node.js is a runtime enviornment that allows JavaScript to be run on the server side. And Puppeteer is a ‘headless chrome node API’ written by google (basically, it allows you to write DOM Javascript code on a server).
Just an FYI, because I love TypeScript, I will be using that for this project. If you want to use TypeScript, please install it on your system. If running tsc -v works in the terminal, you’re good to go!
Okay, to start off, make sure you have Node.js and NPM (Node Package Manager) installed on your system. If you get a command not found or something related by running one of the following, I suggest that you look at this article on how to install Node.
$ npm -v # should be 6.0.0 or higher
$ node -v # should be 9.0.0 or higher
Great! Let’s start a new project and install the dependencies:
$ mkdir Web-Scraping-101 && cd Web-Scraping-101
$ npm init # go through all defaults
$ npm i puppeteer # the google npm scraping package
$ tsc --init # initialize typescript
$ npm i @types/puppeteer # type declarations
Now open the folder in the text editor of your choice. Edit the outDir option in the tsconfig.json file to be ./build and uncomment the line, so it looks like this:

Create a new file in the root of the folder:
$ touch app.ts
In app.ts add:
console.log("Twitter, here we come");
Now, to run this, in terminal, write: tsc && node build/app.js
NOTE: tsc builds all TypeScript files into the outDir directory defined in the config file and node runs a single JavaScript file.
If you see “Twitter, here we come” appear in the terminal, you’ve got it working!
Now, we will start to actually scrape using puppeteer.
Add this boilerplate puppeteer code to the app.ts file:
import puppeteer from "puppeteer"; // import the npm package that we installed
(async () => {
// the rest of the code must be enclosed in an `async` function to be able to `await` for results
const browser = await puppeteer.launch(); // launches an "invisible" chromium browser
const page = await browser.newPage(); // takes the browser to a new tab (page)
await page.goto("https://example.com"); // takes the page to a specific url
// Get the "viewport" of the page,
// as reported by the page.
// NOTE: Anything inside of the `evaluate` function is DOM manipulation.
// No variables outside of the evaluate function can go in, and none can come out without being returned inside of the return object.
const dimensions = await page.evaluate(() => {
return {
// use DOM manipulation to access the width and height of the page
// if you want to get elements out of the DOM and into the node js code, return theme here
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
deviceScaleFactor: window.devicePixelRatio
};
});
// print out the DOM data
console.log("Dimensions:", dimensions);
// remember to close the broser (invisible chromium)
await browser.close();
})();
Please read through the commented code above to get a feel for what is going on ⬆.
Now that you can see how we can travel to a web page, gather info using DOM manipulation, and bring that info back to the Node js program, we are ready to scrape twitter.
First, edit the await page.goto("https://example.com") to be await page.goto("https://twitter.com")
Next, we need to be able to get the posts from the middle column (the actual twitter feed). After some investigating, I found this selector is the one that actually selects the div for the middle column feed:
document.querySelector(
"#react-root > div > div > div > main > div > div.css-1dbjc4n.r-aqfbo4.r-1niwhzg.r-16y2uox > div > div.css-1dbjc4n.r-14lw9ot.r-1tlfku8.r-1ljd8xs.r-13l2t4g.r-1phboty.r-1jgb5lz.r-1ye8kvj.r-13qz1uu.r-184en5c > div > div > div.css-1dbjc4n.r-1jgb5lz.r-1ye8kvj.r-6337vo.r-13qz1uu > div > section > div > div > div"
);
// the above returns the div for the middle column twitter feed
Here is an image of what that represents:

To get all of the images from the middle column, I ended up doing this for the page.evaluate() function:
const dimensions = await page.evaluate(() => {
let sources = []; // an array of the links to each image
document.querySelectorAll(
"#react-root > div > div > div > main > div > div.css-1dbjc4n.r-aqfbo4.r-1niwhzg.r-16y2uox > div > div.css-1dbjc4n.r-14lw9ot.r-1tlfku8.r-1ljd8xs.r-13l2t4g.r-1phboty.r-1jgb5lz.r-1ye8kvj.r-13qz1uu.r-184en5c > div > div > div.css-1dbjc4n.r-1jgb5lz.r-1ye8kvj.r-6337vo.r-13qz1uu > div > section > div > div > div img"
).forEach(img => {
if (img.src) {
sources.push(img)
}
});
return {
sources
}
}
Now if I want to compile a list of all of the image sources and print them out to the console, all I have to do is write this outside of the page.evaluate() function:
console.log(dimensions.sources);
There you go! You’ve just scraped image data from a twitter feed. A challenge would be to take this data and integrate it into an express server so that when a user goes to the root site, they are presented with all of these images.
Thanks for reading!