Activation functions comparison
12 Feb 2020Consider a neuron. All it does is calculate the sum of its “weighted” inputs and adds the bias on that:
!!y=\sum (weight \times input) + bias!!
Because Y can be any value from (-inf, +inf), activation functions are the deciding factor of whether a neuron should fire or not (be on or off, 0 or 1, etc.)
Why use an activation function? Well, there are a few good reasons, the most important being that activation functions introduce non-linearity into the network. A neural network without activation functions is basically just a linear regression model and is not able to do more complicated tasks such as language translations and image classifications. Also, linear functions are not able to make use of backpropagation which is the way neural networks “learn”.
Step Function
This is a function that says:
$Activated=true$ if Y > some number (usually 0), otherwise 0
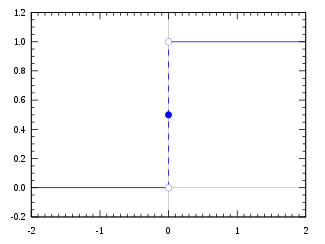
What happens when there are many different neurons that are all 1 or all 0 or some are 1 and some are 0. How do you decide which is most right? This is what activation functions help with.
What if I had some function that could tell me which is most right….20% right 99% right 87%, etc….
The first thing that comes to mind is a Linear Function:
!!A=cx!!
This way it gives a range of activations and given many neurons we could choose a max or min or something else.
The problem with this is that the derivative of this linear function is a constant which means that in the back-propagation of the network, the derivative will never go to zero and find that “minimum”. It will keep climbing slowly to either +inf or -inf.
Let’s now look at a function that can give us a range of results but is non-linear.
Sigmoid
!!A=\frac{1}{1+e^{-x}}!!
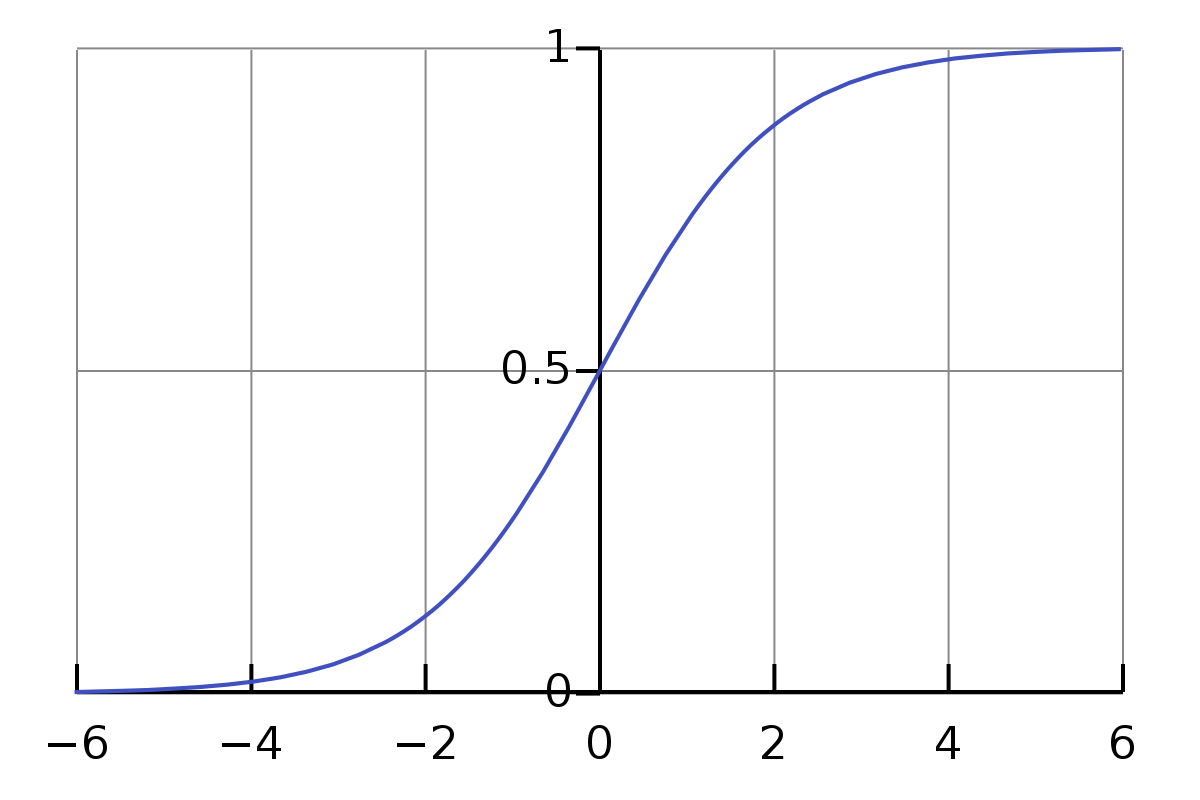
Benefits of this ‘step’ function:
- Non-linear
- Binary (ever output is either above, below, or equal to 0.5)
- Smooth gradient
- Always will be in the range (0,1) so values are kept close together
A downside of the sigmoid function is that towards the ends of the curve, y values (outputs) tend to respond very little to changes in x ($\frac{dy}{dx}$ is close to zero). This means that the gradient is small or has vanished entirely which gives useless results for inputs that are higher than about 6 in value.
Tanh
!!tanh(x)=\frac{2}{1+e^{-2x}}-1!!
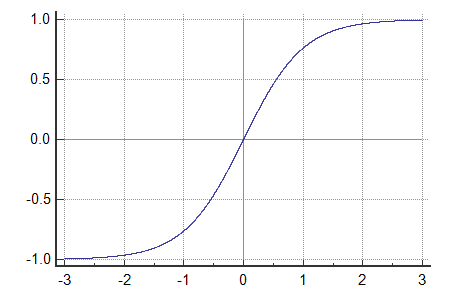
As you may be able to see, it is a scaled sigmoid function:
!!tanh(x)=2sigmoid(2x)-1!!
About the Tanh function:
- Non-linear
- Is in range (-1,1)
- The gradient is stronger for tanh that sigmoid (the derivatives are much steeper more of the time)
- Like sigmoid, tanh also has the vanishing gradient problem towards the ends
- Like sigmoid, it is very popular — libraries support it
ReLu (rectified linear unit)
!!A(x)=max(0,x)!!
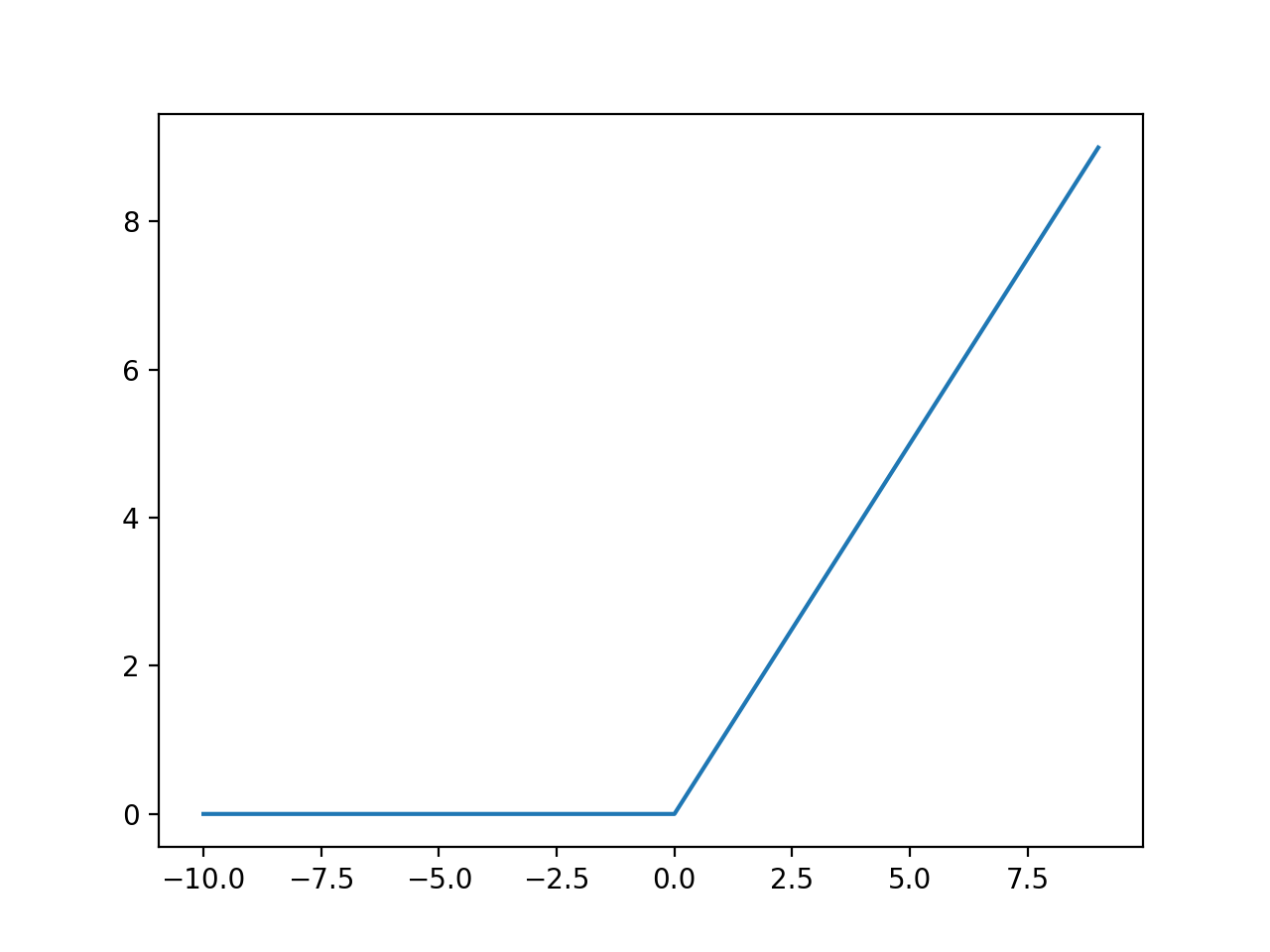
About ReLu:
- Non-linear in nature.
- Not bound (darn!)
- Range is [0, inf) — can blow up the activation
- Not as computationally costly as the other functions
- Involves only simple mathematical operations
- Because of the horizontal line for any negative x values, the gradient can go to 0 and nothing changes in the back-propagation step— this is known as the “dying ReLu problem”
Which one??
Sigmoid has proven to work well on classification problems, however, both sigmoid and tanh suffer from the “vanishing gradient” issue. They are generally not recommended nowadays because of loss in performance and accuracy in deep neural networks.
The ReLu activation function is widely used and is the default choice for many as it yields better results although it should only be used in hidden layers because the model can suffer from dead neurons or infinite max out otherwise. If you have a regression problem, then the final layer of your network could possibly use a linear function (though not recommended a ton when using it in conjunction with an ANN).
I hope this article helped clear out some misconceptions or confusion around the different activation functions!